- [1] Reference embedding: Skerry-Ryan, RJ, Battenberg, Eric, Xiao, Ying, Wang, Yux- uan, Stanton, Daisy, Shor, Joel, Weiss, Ron J., Clark, Rob, and Saurous, Rif A. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron. arXiv preprint, 2018.
- [2] Global style token: Y. Wang et al., “Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis,” vol. 1, 2018.
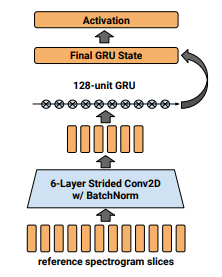

Global style token은 Reference embedding에 대한 연구를 기반으로 하고 있다.
Reference embedding에 대한 연구에서 사용한 reference encoder와 동일한 encoder를 쓰지만 더 발전시킨 점은,
훈련데이터/reference 음원(추론 시)에서 뽑은 reference embedding을 n개의 global style token들의 weighted sum으로 변화시켜 표현한다는 것이다. 이렇게 global style token의 weighted sum으로 표현된 embedding을, reference encoder의 출력인 reference embeddidng과 구분되게, style embedding이라 한다.
이 과정에서 n개의 global style token들은 이들의 조합이 최대한 다양한 reference style들을 표현할 수 있도록 학습된다. 말하자면, style token들은, 제한된 토큰 갯수로 reference embedding의 space를 최대한 잘 표현하기 위한 basis vector라고 할 수 있다.
Q) 이렇게 reference embedding을 global style token을 사용하도록 수정했을 때 얻는 이득은 무엇일까?
- 추론 시에 어떤 음원의 스타일대로 했으면 좋겠다는 예시인 reference embedding을 매번 제시하지 않아도 된다. Global style token들은 훈련 데이터에 있었던 눈에 띄는 특성들을 각각 학습한 것이므로, 이 토큰들의 weight을 제시함으로써 원하는 스타일로 합성할 수 있다.
- Generalization이 잘된다. Reference embedding을 global style token들의 weighted sum으로 표현하는 과정에서 global style token들은 generalizability를 학습하게 된다. Reference embedding을 가지고 합성을 하려 했을 때는 reference 음원과 추론 문장 사이에 길이 등의 차이가 크다면 reference 문장과 비슷하게 스타일링을 할 수 없어, generalizability가 떨어졌다면, global style token을 활용한 방식은 이런 제약을 완화했다.
Q) Global style token의 한계는 무엇일까?
Global style token 모델이 style token을 학습하는 것은 훈련 데이터에서 패턴을 학습하는 것이다.
즉, 훈련 데이터가 일반인이 일상 대화를 한 것을 모아놓은 DB라면 global style token 모델에서 유의미하고 흥미로운 token을 학습하지 못한다. Global style token은 성우가 연기를 한 오디오북 DB를 전제로 하는 모델이다. 성우가 다채롭게 연기하는 큰 오디오북 DB가 없다면 Global style token은 고만고만한 style token들만 잔뜩 학습한다.
따라서 일반인이 30분씩 발화한것, 또는 연예인이 30분 정도 발화한 것으로 합성기를 훈련해 오디오북을 만들고 싶다면 Global style token은 답이 아니다. 이와 관련해서는 최근 Interspeech에 제출된 아래 논문이 이 문제를 다루고 있으며, 소스코드 및 pretrained model까지 공개되어 있다. 남녀노소 한국인 159명의 목소리로 합성할 수 있으며, 일반인의 음성을 stylish하게 바꿔주기 때문에 감정 발화, 경상도 사투리, 전라도 사투리 등으로 합성이 가능하다.
Pitchtron: Towards audiobook generation from ordinary people's voices
논문: https://arxiv.org/abs/2005.10456
소스코드: https://github.com/hash2430/pitchtron/
hash2430/pitchtron
한국어 사투리 합성기. Korean dialect prosody transfer. TTS for pitch-accented language - hash2430/pitchtron
github.com
Pitchtron: Towards audiobook generation from ordinary people's voices
In this paper, we explore prosody transfer for audiobook generation under rather realistic condition where training DB is plain audio mostly from multiple ordinary people and reference audio given during inference is from professional and richer in prosody
arxiv.org
'TTS' 카테고리의 다른 글
| Japanese/Korean/Vietnamese Corpus (0) | 2020.02.08 |
|---|---|
| Bytes are all you need (0) | 2020.01.21 |
| Deep Voice 3 (0) | 2020.01.17 |
| Transformer TTS (0) | 2020.01.17 |
| Tacotron2 (0) | 2020.01.17 |

